Page Not Found
Page not found. Your pixels are in another canvas.

A list of all the posts and pages found on the site. For you robots out there is an XML version available for digesting as well.
Page not found. Your pixels are in another canvas.
About me
This is a page not in th emain menu
Published:
In this episode, we want to investigate a simple working neural network (NN) anatomically, without the use of any deep learning package. You might find it very interesting to design every single element that is essential to perform forward and backward propagation. Every piece of component can be put up together like playing a LEGO game!
Published:
To have $\LaTeX$ equations on this website, which is run on Github Pages using Jekyll and AcademicPages (a fork of Minimal Mistakes), I had to make a few guesses, so here are the secrets.
Concert, Jockey Club Auditorium, the Hong Kong Polytechnic University, 2023
Featured Music:
Short description of portfolio item number 1
Short description of portfolio item number 2
Published in J. Am. Statist. Assoc., 2026
Real-time learning from streaming data! We propose a one-pass, time- and memory-efficient method for high-dimensional GLMs—Adaptive Debiased Lasso (ADL)—that updates coefficients and standard errors on arrival via stochastic gradients with online debiasing.
Recommended citation: Han, R., Luo, L., Luo, Y., Lin, Y., & Huang, J. (2026). Adaptive debiased lasso in high-dimensional GLMs with streaming data. J. Am. Statist. Assoc. (to appear).
Published in KDD, 2026
Architecture‑dependent, non-asymptotic regret bounds that can be sharpened under a simple margin condition (when human preferences are more “clear” than you think).
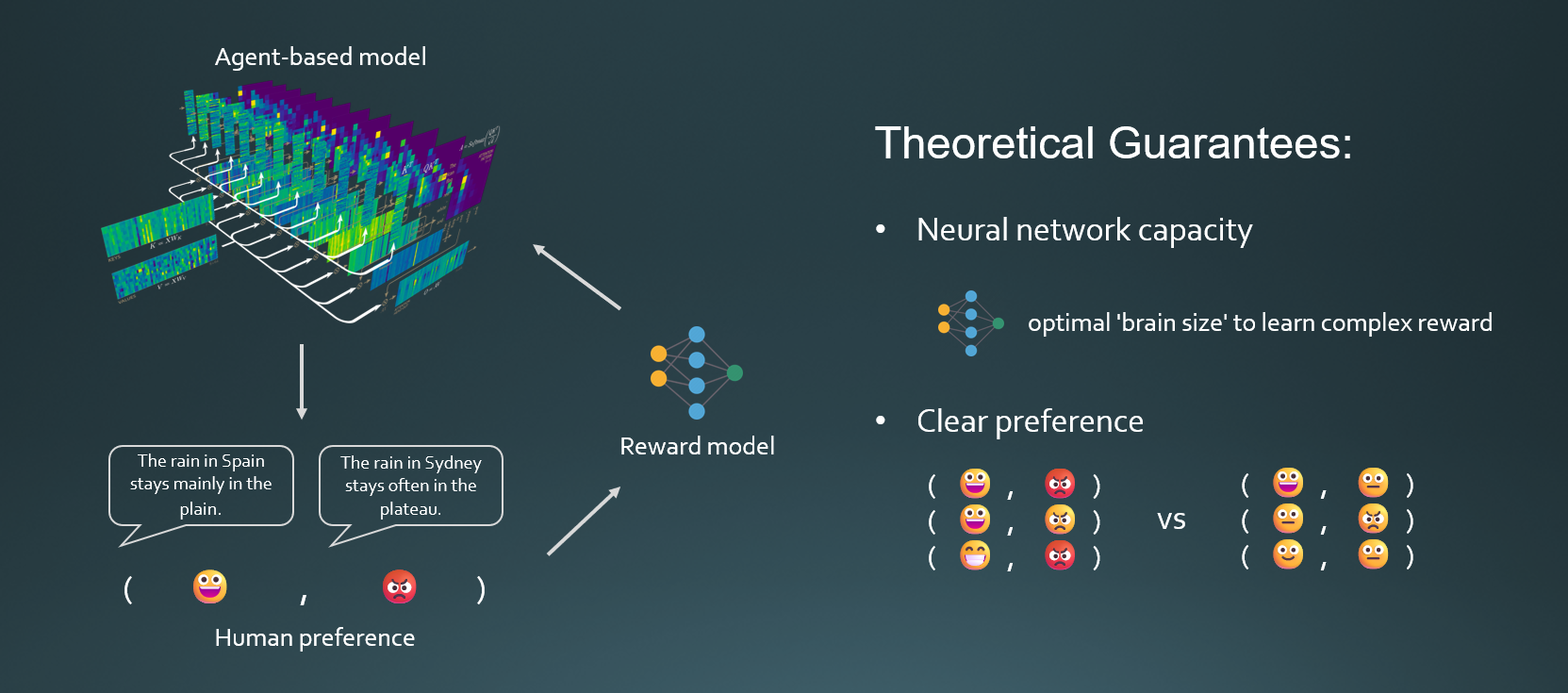
Recommended citation: Luo, Y., Ge, Y., Han, R. & Shen, G. (2026). Learning Guarantee of Reward Modeling Using Deep Neural Networks. SIGKDD2026 Research Track (to appear).
Published in submitted, 2026
Do you follow the ATP tennis tour? Have you ever placed a bet at the race track? Who is the G.O.A.T.? Whether it’s ranking sports legends or training the latest Large Language Models (LLMs), the challenge is the same: how do we find the best when we cannot compare everyone against everyone?
Recommended citation: Fang, X., Han, R., Luo, Y. & Xu, Y. (2026). Recent Advances in the Bradley–Terry Model: Theory, Algorithms, and Applications. arXiv preprint arXiv:2601.14727.
Published in submitted, 2026
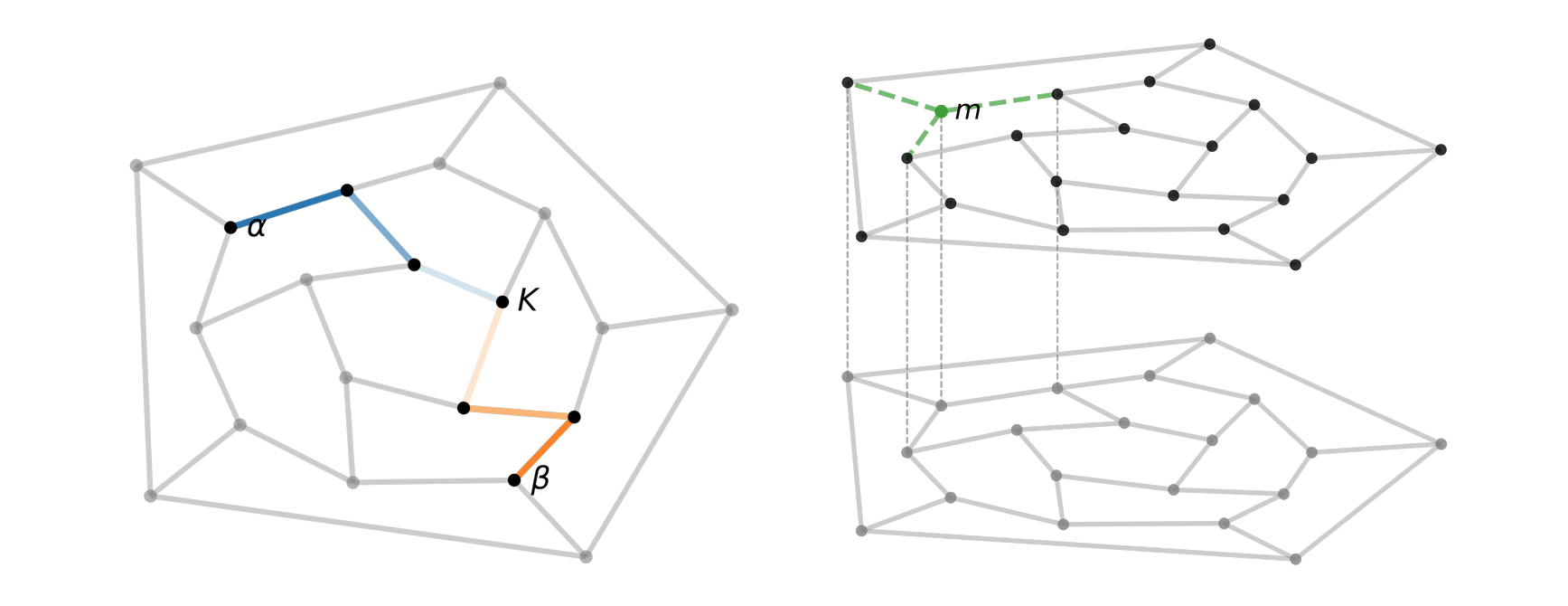
Why does A beat B, B beat C, but C beat A? In standard theory, this is a paradox. In our framework, it is simply a missing dimension.
Recommended citation: Luo, Y. Fang, X., Han, R. & Xu, Y. (2026). Deep Ranking with Heterogeneous Effect. arXiv preprint arXiv:
Published:
This is a description of your talk, which is a markdown files that can be all markdown-ified like any other post. Yay markdown!
Published:
This is a description of your conference proceedings talk, note the different field in type. You can put anything in this field.
Workshop, University 1, Department, 2015
This is a description of a teaching experience. You can use markdown like any other post.